Back again! Literally years since my last post. Is blogging back? It feels a bit like people are slightly more excited about self-hosting content again than they have been in a couple of years, it's true. The big incumbent social networks are feeling a bit less solid than they used to. Facebook has been laying people off and visibly throwing money away chasing a dorky-looking, implausible VR business that almost nobody (save for the investors) seems interested in. Twitter has gone private, rather publicly, and at the time of writing seems to be in the process of reinventing itself as Twitter 2.0, whatever that turns out to mean. Right now, it seems to mean far fewer people posting, looking at my logged in timeline. Mastodon is having a moment. Maybe blogging is back!
While I am mildly excited by these winds of change, none of this is really anything to do with my sudden return to posting. My motive is something considerably less idealistic. I've moved web-hosts again, putting this post clearly into the least exciting, yet most solipsistic form of personal blogging, namely, updates on infrastructure and apologies for lack of content, addressed to an almost entirely imaginary audience!
My motive for moving hosts is worth a minor note, and also feels very 2022. My hosting costs have shot up so much, primarily due to the dramatic surges in energy costs of the past six months, that it no longer seems economically viable to use even cheap commercial hosting to prop up a vanity website I barely make any use of. So I've taken the very retro step of bringing it all back in house. Literally in-house, this page is now running off a tiny low-power media PC repurposed as a basic Linux server, connected up to my home DSL connection, and sitting in the cupboard behind the television in my front room. I had fun doing it, but it was an extremely manual process, and as a result of that I'm quite sure there's a few bugs and glitches hanging around, and some stuff will be weird until the all of the DNS edits are fully propagated.
You wait six months for a blog post and then I suddenly update all the things at once. Here we are. Site redesign. New Server. New software release. Lets tackle those in order
Redesign
I launched this version of my blog originally as 'in-progress' software before it was quite ready, after spending a few years faffing around with experiments intended to replace WordPress. One day I had something I wanted to publish, and WordPress was broken, and the thing was nearly working so I hit go. It wasn't feature complete, and there was completely minimal styling, but I thought it looked OK enough, until a friend pointed out it looked completely insane on a mobile. I felt pretty embarrassed, so I quickly cobbled together a mobile-first grid-oriented thing using zurb foundation 5 as a framework, because that was what we were using at work at the time, and it seemed like an excuse to learn a bit about how it worked. I subsequently reworked it to use foundation 6 with a slightly styled theme based on my old WordPress colours and there we are. Of late, the amount of gubbins needed to support the foundation classes has been a bit of an encumbrance, and so I decided to do away with it. This time I just hand-wrote the styles again, I think CSS has moved on a bit and hope browsers are generally a bit better behaved. Seeing as we were doing this, I did a new theme, it's based on my emacs colours. I don't care that you hate it, no.
New Server
I'm sure you all heard, ARM hardware is the new hotness now. As a natural contrarian, I was already hosting my site on an ARM server and so it's clearly time for me to move to AMD64. Not quite. For years I've been having fun hosting this place on one of scaleway's ARM C1 instances, which appealed to my quirky taste in alternative computers, as well as being super-cheap, and in many ways, offering far better raw performance than a VPS or a cheap cloud instance. Seriously. I was running about twelve services per instance, and my own hand-written site software, and performance was more than acceptable. I even hit the front page of the reddits and the orangenews a couple of times with my tech dithering, and soaked up big blog traffic spikes, no sweat. However, scaleway haven't offered any useful updates to their core platform since they experimented with, and withdrew a 64 bit ARM beta, and now seem to be moving more towards a VPS/Intel vision, and it was really becoming a bit limiting to be stuck on Debian 9 and 32 bit. So I moved house, installed some containers on an existing server I had sitting around and now we're live, in Belgium .
New software release
This is a little bit tied in with the last item there. The site engine here is written in common lisp, and for the longest time I just had it running out of an interactive repl attached to an emacs. Yes, including the #1 NackerYews story days. I moved it to a systemd service, for process supervision, and proper logging and things like that, and I wanted to get some kind of release management regime in place. So I had a fun time figuring out good ways to build standalone lisp apps, and how to package them up for Debian, and now I kind of have tagged release builds. I'm also running in my own cowboy cloud, sticker-ed together out of LXC, so the blog now can be deployed as a clean, ephemeral contained service any time I want to do a release. Particularly this part of things was becoming quite the aggravation, cross-building for ARM32 isn't really trivially feasible with common lisp, and although I had a lot of fun for a bit building debs on a raspberry Pi tucked under my desk, I eventually ran out of patience trying to keep ABI back-compatibility with older Debians.
Devops
My process probably seems a little bit archaic and convoluted to anyone used to thinking about this kind of thing in a modern context. It is true that there are lots of simpler abstractions and services for doing this kind of thing these days. Perhaps less intuitively, doing things the bale-of-twine and pencil sketch cowboy manner I've pitched for is also crazy easy compared to what I remember hand wrangling sites of old used to be. LXC is fairly straightforward to install on Debian stable OOTB. (unprivileged mode is still a bit of twerking, but if you follow the recipe exactly, straightforward enough). Debhelper vastly simplifies deb building (although I'll concede you do still have to do way too much) and gpb is simpler yet in some ways. Quicklisp, buildapp and quickproject make lisp dependencies and builds almost pleasurable. Cloudflare and certbot wildcards make swapping hosts around with full TLS almost disconcertingly straightforward compared to what I've been accustomed to in the past.
Of course this is still a rolling set of dependencies which may appear complex or unfamiliar, but in a lot of ways there's also a whole lot of faff and bookeeping overhead removed, no accounts or APIs, third-party apps and frameworks to keep up-to-date. Most of this task list was concerned with a full bootstrap from a naked host. For ongoing support I just have to compile debs using standard make, launch empty containers with standard templates, and write posts and maintain code with a straightforward text editor. And there's complete autonomy of hosting and running, I'm not really locked into anything, which is exactly where I prefer to keep things. The modern-day indieweb refuses to die!
I can remember fairly clearly the first time I seriously tried to calculate the future . I was maybe ten years old, lying in bed and re-reading an issue of 2000 AD, and for the first time, I was puzzling over the idea that that title, intentionally and inherently futuristic, represented a real calendar date that would one day arrive, and somehow, calamitously render the name obsolete. I tried to figure out how old I would have to be by the time we reached this epoch, but as I recall, it was beyond my reckoning. It didn’t seem that likely I would live long enough for vengeful androids and routine interstellar travel, and yet even from 1977, the year 2000 seemed countable. And here I am, now, in 2020, A number that looks so impossibly, so implausibly of, from, and for the future my brain isnt really comfortable holding on to it. But first we must put away 2019. Here's my 2019 roundup, in something like 20 paragraphs.
I rejoined social media:
2018 I had a year off Twitter, feeling a bit exhausted by it all. It didn't really seem to make much difference. Now the Internet seemed to have invaded, occupied and consumed everything. Surveillance capitalism now so entrenched it was to be a regular part of mainstream think piece commentary. Network effects being what they are, It’s deluded and futile to make even token efforts to keep beyond these tracking networks, the reach is now such that secondary and tertiary associations will just link around you and pull you in anyway. So I bounced back onto Twitter, signed up for Instagram, and even rejoined Facebook-and rectivated Foursquare. I’m not particularly excited by any of them. At best, they represent a low friction way of posting light life updates, and it's nice to get reciprocal insights back about people I know, but don't see regularly. (And now I don't really see anyone regularly, so that’s a thing) It's fine, but we can do better. Ironically 2019 feels like the year everyone started to gently pull back from all this online sharing stuff. Ho hum.
Gene Wolfe died
Boo. Probably my favourite author, genre or otherwise. Age 87, which is by any account a splendid innings. A couple of personal resonances last year. I finally finished reading the “solar cycle”, which contains some of my most loved books. I started when I was fifteen, and I was just starting into the final volume when he died. And then the Folio Society issued a fairly exquisite luxury edition of his masterpiece, "The Book of the New Sun", signed, numbered and limited to 750 pieces, and which I somehow managed to discover and purchase before they sold out. I felt pretty decadent, and guilty about spending hundreds of pounds on a fancy copy of a book I already owned, but within weeks people were listing them on eBay for thousands, so maybe it was a wise investment? Anyway, Wolfe is amazing, and-if you havent read him, why not try? Start with the Fifth Head of Cerberus, I would.
A Haircut:
by the end of the year, I was bored of the hair, so it's all off again. I suspect the next time it grows back in may well be all white.
An ASD diagnosis:
No not me. We've basically known about it for a long time ourselves, and painfully been pursuing a diagnosis through the systems for literally years, but late in the year we obtained a professional diagnosis of ASD for number one child. Shock, relief, and lots to process for everybody, but a powerful sense of progress in a way that feels constructive and enabling, not reductive and labelling.
Weddings x2:
Here's a surprise ageing effect. Having got past "peer group wedding” season, and assuming weddings were all done I seem to have hit "generation below hits wedding season" season, and now weddings are a thing again. That's cool, I like weddings. This summer was two, both fancy AF. One in a cathedral, one in Cyprus. The latter was an Orthodox church service, which was quite unlike anything else I have previously experienced. Weddings are a pretty big deal in Cyprus.
Castles:
Throughout 2019 we held a family membership to English Heritage, and as a result spent a few weekends wading around ancient English castles. There are quite a few spectacular examples In this part of the county, closest to the mainland (we can see France very with the naked eye most days). Dover is particularly astonishing. Pretty middle-aged, I guess. National Trust next?
Photography:
I've been getting gently back into using actual cameras for photography. Maybe inspired by instagram? Possibly just because my predilection for "alternative" smartphone operating systems lumbers me with dreadful quality camera software? Regardless, I have been having fun shooting things with real glass - on my much loved power shot GX9-2, which sadly caught some water damage on a recent trip to Malta and is still drying out four months later - but this gave me an excuse to upgrade it to a slightly larger slightly more posh Canon M100, which is more cumbersome and not quite as fun to use, but easily compensates for that in image quality and lower light performance. I don't even muck about with much manual selection, mostly plain automatic shooting, but I really enjoy something about the deliberation, and the ceremony, and having to actively curate, triage and extract the images off the camera in order to use them for anything. Mindfulness? Contrarianism? Whatever, Fun.
Still in Folkestone:
Yup. After quitting London to work remotely, we sold the big house, and shifted even further south to Folkestone, where I remain, the most mundane kind of digital nomad imaginable. I like it a lot. I was born by the sea, I grew up by, in and on the sea, and now, once again, I walk, with god, alongside the actual sea, most days. I've even gone in it to swim. Folkestone is my kind of town really - collapsing Victorian splendour, a harbour, vague touches of bohemia, light gentrification, that isn't trying too hard, and you can clearly see France most days, without effort, and that is something I will never not find mind-bendingly magical.. It does rain a bit too much, mind you.
Dental surgery:
2019 Was the year I finally gave up pretending I could largely ignore the pitifully untended state of my teeth. Actually, it was the teeth that made the decision for themselves. I have a pretty strong dental phobia (Maltese dentistry in the 1970's was not great), but by the middle of the year something was painfully not right in an area that had been slightly bothersome for years, and pain was escalating alarmingly. I still couldn't manage the appointment making myself, so thanks to my lovely wife, I ended up enrolled with a local private practice, and with a fairly gruesome diagnosis : -an impacted wisdom tooth had grown down into my jaw and accessed, destroying two molars, and threatening jaw damage. Surgical intervention was required, and due to my panic-stricken inability to co-operate, it was to be done under a still fairly Terrifyingly named process of "conscious sedation". That meant a referral, three months of waiting for a slot at a specialist clinic, and an almost constant diet of pain-killers in the interim (as well as two very uncomfortable, and strictly speaking forbidden, international flights) but eventually I got through it. The conscious sedative was one of the most surprising experiences I have ever had. Strapped into a chair in a small theatre, and attached to a drip, I remember a brief chat about consent, and then the next thing I remember I was in the passenger seat of the car on the way home, a mouth full of wadding, having entirely lost a couple of hours and a couple of teeth! I am left wondering if I was out for the operation, or if I have simply retained no memory of it, and what precisely is the dittoed between those two anyway? I find the very existence of this kind of instant blackout drugs and astonishing and implausible marvel. If It were a plot device in a fiction, I'd have scoffed at how completely unrealistic it was. So now I have a dentist, a treatment plan, no headaches, and two Fewer teeth. Lots more work needed, but it feels achievable. And I’ve experienced time-travel.
Common Lisp@work:
Love this one. My day job is still working at platform.sh, where we have a home grown container runtime that powers our "cloud" project. Cloud engineering is my team, and literally my first act in the job was to port one of my existing lisp web apps to the runtime as an experiment. Well, it turns out our VP of engineering is also a lisper, and we have ended up extending these experiments to building a couple of internal tools in SBCL, which are of course hosted on the platform. These proved useful enough to keep, and at that point, it started to make sense to productionize the lisp containers, so we can have a first class and maintainable build, rather than shoehorn a lisp install into a capable enough container. At which point there was no reason to not make this publicly available for customer projects, which we announced with a blog post, which was well recieved on the social platforms. I only had a tiny part in all of the above processes, but it is still one of the coolest things I have ever been involved with at work and remains a woeful reminder that I have a pretty cool job and work with a great team.
A-Rank in Splatoon!:
I adore Splatoon, Nintendo’s gloriously styled paint-em-up, online FPS. I’ve been playing it quite regularly since launch on the Wii U, and through into it's subsequent re-packaging as Splatoon 2 on the Switch. I love everything about the game, from the mechanics, which are well-considered and balanced, all the way through to the world-building and the whole skate-tween-punk cartoon fish aesthetic. I mostly play ranked, and although I wouldn't claim to be particularly good, 2019 was the year I finally sneaked A rank after years of trying. And not just once, but in a couple of categories (zones, tower, and rainmaker) Yes I realize this is because fewer people are still playing. What of it. I have a badge.
TV:
I watch a lot of TV. and I'm not ashamed of it. I know we're living through peak TV, but for me 2019 was a less than stellar year. Plenty of things, I probably should like, I just didn't. I dont have much appetite for "The Apprentice" anymore, although it can still deliver hilariously awful situations from its contrived casting. “Fleabag” annoyed me almost as much as it charmed. Star Trek regularly sent me to sleep (love the art direction still). The concluding series or Mr Robot was great, I've thoroughly enjoyed that whole run, but it was time to sign off. "Homecoming" wasn't quite so great, but it worked. I think my favorite show from last year would have to be discovering “Crazy Ex-Girlfriend” on Netflix (awful title. do try to get past the title) - Super-smart, subversive , unpredictable, bingeable, engaging, and great music. I was already a huge Adam Schlesinger fan, and now I guess I'm a Rachel Bloom fan too. So many earworms. Bring back old Greg!
Books:
I suck at reading, these days I know it's a common modern Iffliction. I have been trying to make an effort. I finished the Gene Wolfe Solar books, as I mentioned earlier, but otherwise 2019 was not so great. According to my Goodreads account (doesn't capture everything but it's fairly accurate) , I only managed nineteen books, some of which I can't even remember reading. Aside from Wolfe, I think my high points would have to be "The Peripheral" and "Ingenious Pain" . 2020 we have a sequel to "The Peripheral" due, as well as the final installment of Hilary Mantel's Cromwell books and I'm going to do better. Im trying to do ten minutes entirely focused reading a day this year. Going well so far (2 books finished already)
Movies:
I'm still struggling here as well, although we do a weekly family movie night, I still rarely get to the cinema. I did make it to see “Rise of Skywalker" and this I did manage to see every Star Wars movie on initial cinema release. I'm afraid the most enthusiasm I can find about that is that I’m glad it's done. Similarly, on the other franchise I finally got up to date with Marvel by reaching “Avengers: Endgame" on streaming, and I'm mostly happy to be able to say “OK, this can stop”. The kids got into Harry Potter, having reached that sort of age, and so I also belatedly got to the end of those, and my goodness they're bad. Things, I actively liked- “Lady Bird”, Netflix's "Annihilation" was superb, and my favourite was probably "Sword of Trust". And on Xmas Eve I decided to watch an ancient favourite, "Lair of the White Worm" which I enjoyed revisiting so much, I may make it into a Xmas tradition from now on. Ken Russell(I) is my man.
A New kitchen:
Our kitchen seemed to be in relatively good shape when we bought the house, but it had a conservatory attached to where the back door ought to be, which although it made for a lovely sense of light and space was punishingly cold in the winter. So we decided to get a glazed back door fitted between. And then we found rotting wallpaper trapped behind the kitchen units over damp plaster, and decided to get a nicer fitted kitchen while addressing that. And then we discovered a water leak running down the back wall. And then a cascade of horrors, including a lintel-free window, a removed chimney being held up by what looked like a nail through an old chair leg, three layers of wall cladding, and perhaps most excitingly, several rotten joists not doing the greatest job of keeping the upstairs upstairs. Cue months of no kitchen, stripping everything back to brick, jacking up the roof, replacing beams, dry lining everything. and then potting in a kitchen back on top. And now we have a back door. And quite a nice kitchen. And far less money.
Malta & Cyprus:
Two Foreign holidays? I already mentioned my friend's magical destination wedding earlier, but by way of attending we got to spend almost a Week, without children, (thanks, Grandma!) in a pretty swanky hotel in Limassol. Cyprus is hot in the summer, and I say that as someone quite used to heat. So I ended up doing something I have never done before, and just hung out poolside, reading, and swimming and being waited on. And that was just great. And Despo came by to visit, which was a lovely coincidence. Then, a couple of months later we all went to hang out in another resort hotel, but this time in Qawra , in a Family oriented holiday complex. That's the first time we've done significant overseas travel as a family, also the first time I've been back in Malta in almost a decade. I enjoyed the opportunity to show the girls a little of the sense of what Malta is like, and I stole away for a poignant solo visit back to my old home town, my last opportunity to do it as a full EU citizen.
Softwares:
I am feeling quite out of love with computers and software, and especially the flipping internet and the incessant noise bubble of the tech industry. At the moment, I'm afraid to say, outside of work (work is cool, as mentioned already) I’m not really indulging in very much computering. A brief spurt of activity on a secret, not yet abandoned, but not yet revisited project, at the start of the year, and then nothing really - a few isolated sessions of hacking on the software for this site which only really focused on infra things and build chains - I guess I have a useable flow for generating 32 bit ARM debs from Common Lisp applications, but that's more bureaucracy and housekeeping than hacking, and even I don’t find it that enthralling. And most of my infrastructure is still a mess after moving. Maybe 2020 I'll find a way to relight the spark. Maybe I'm done ? Seems unlikely, but I’m not inspired.
I love my new shaver:
On a more positive technology note, I did fall severely in love with a piece of consumer electronics. I finally lost patience with my Philips rotary head shaver, after years of dissatisfaction and overspending on replacement foils and cutting heads that never really helped much. Not really knowing where to turn to for advice, I tried the wire cutter, something I’m a little wary of trusting and I picked up a Braun series 7 during Black Friday month at amazon.co.uk, and no exaggeration, It has COMPLETELY CHANGED MY LIFE. I am competely astonished at the ease of use, enthralled by the consistency of the result, and enraptured by the sense of considered Germanic engineering that exudes from every aspect. I love this thing and it makes me happy while I am using it.
No music:
I am barely listening to anything. Some of it is because I've barely strung my music library infrastructure back together after relocating. Some of it’s because I'm too old and boring and middle aged. Some of it's because I still don't have a subscription to a streaming service, and some of it's just because I think I have just lost the habit of it. I have been playing guitar much more in the past 12 months than in previous years, and l am flirting with writing and recording a little bit more again. 2019 though, is a solid musical wash-out.
iOS WTF:
I know! I'm back on (an) iPhone after YEARS away. Actually, I jumped via an iPad first. I’ve been enjoying this fanciful idea of multiple, task-specific devices, and I wondered about splitting the non-coding, computer things away from my laptop and I thought I'd give an iPad mini a try-out as a general-purpose 'personal' computing device; Apps, email, browsing, etc. It was a mixed success- I use it for some things way more than I expected I would, it is basically the only way I do email now, I have used it to write the entirety of this blog post. (by hand, with a pencil!), and a bit less for others (I had a quixotic notion that I'd finally get everything organised into digital calendaring but I still remain a barely calendared human) Overall though, I likes it. It’s very reliable, I’d say it’s a slightly more useful thing than it appears to be on the surface, and a slightly less capable thing than it appears in the advertisements. I'm quite happily onboarded now though, to the point that I feel comfortable treating it as the primary device / silo for certain categories of things. So much so that when I hit a patch of phone trouble with my Sony Xperia 2 running /e/ (This year I have bounced between Lineage, /e/ and SailfishOS in my continuing adventures in alternative phone systems) I decided to dust off an almost dead iPhone 6S and give it a try. And, it's fine. Fine enough that I refurbished the battery myself, which cost fifteen pounds, and was surprisingly straightforward and kept going. Several months on, I'm still using it. Although not all that much. I think one of the side effects of moving more of my "app stuff" over to the iPad is that I'm not really using my phone for anything much these days beyond light social networking, messaging and podcasts. Oh yeah , and Apple Pay everywhere! I love Apple Pay almost as much as I love my electric Shaver. It is quite peaceful not having to care about whether my phone is working or not when I need to take a call.
A few months ago, I hacked together a kano system to give the children an introduction to computers and what everyone seems to want to call 'coding'. I like the idea, and the style of the kano kit , but I was a little bit dubious about dropping a couple of hundred quid on a 'edutainment' project that might prove to be of little lasting interest. I'm not particularly hung up on the kids achieving productivity with the thing, but if I'm going to increase my pile of computery devices, I'd prefer to invest in things that are going to be useful.
I hacked together my own Kano
Like so many recent consumer 'DIY' hardware kits, the kano systems are built over the super-popular Raspberry Pi single board computer system. The nice kano people provide downloads for their base system (which is built over linux), as well as all their educational software. So, you can fairly cheaply assemble a scratch-build system from parts, especially if you have most of the parts already lying around in your gigantic pile of computery devices, which of course, I mostly do. You just need a screen, a Pi, some input devices, and a suitably-sized SD card to flash an OS image to. (Use this app!)
It all works fairly well. They bundle a collection of educational free software, including the usual suspects (Sonic Pi, Scratch), some slightly more suprising and fun inclusions (Minecraft Pi Edition), and their own 'Kano Blocks' programming system, a kind of scratch-like skin over maybe Python and JavaScript (I haven't really looked into it too much). Most of the value add comes with the user interface kano have used to tie all this together - it's got a nice colourful simplified desktop, and an onboarding script that uses a charming story-telling metaphor with an unfolding narrative (that starts out in a UNIX shell!) to nudge you into a 'learn to program' RPG style adventure. This takes the form of a Zelda style game that walks you through various scripted programming assignments, with a kind of quest structure. The backstory is sort of an updated spin on 'little computer people'. Overall it's quirky, charming, and seems to be quite engaging. Certainly, more appealing and welcoming to younger children than something like a bare Raspbian desktop with the various apps installed.
I think designing user interfaces is really hard. I've done a bit of it myself. To my mind, it is at least as hard, perhaps harder, than writing computer software. On this front, despite a few rough edges, I've been really impressed with how well the Kano design caters to it's audience. By and large, it's pretty suitable for reading-age children to work with mostly unsupervised. (Pleasingly, there's no requirement for a network connection). That's quite a feat. It's not iPad-easy, but it's offering a significantly more freestyle, open-ended computer experience. I had a tiny bit of troubleshooting with WiFi drivers, and sound initially (hey, it's linux on the desktop after all). I expect these wouldn't present if you were using the official hardware kit. I would give a gentle recommendation of kano to anyone that was thinking of introducing a 6-8 year old child to 'computing' in a useful sense. Most of our interface struggles came from a less expected direction...
Intuition
Kano uses a tradtional desktop metaphor, which expects you to have a keyboard and a mouse/trackpad. It's straightforward adding these to a Pi. You can use any standard keyboard or mouse. Your options are USB type A, or Bluetooth. As you might expect, I have piles of these lying around. As it turns out, mostly these are Apple devices, because of historical reasons. These seem ideal. Apple! The fêted industrial design company. Really well built, attractive equipment. Attractive. Robust. World-beating, reliable Bluetooth stack. I had a small parts bin to choose from. Wireless and wired. Mice and trackpads. Aluminium and polycarbonate.
They kind of worked as well as you'd expect. Except the children found them too confusing to use. It turns out, they're riddled with implied behaviour. Multitouch click behaviour for left and right clicks. Or completely invisible mouse 'buttons'. Weird icons for SHIFT, and TAB, and ENTER, and CAPS that are mostly subtle variations on the same symbol. Granted, I'm using the devices outside their expected context, but I was struck by the irony of how unintuitive all of this was, and also how unneccessary. I can appreciate that there's an aesthetic at play here. From a decorative perspective, there's a tasteful and consistent minimalism that ties it all together. I don't think it exhibits good design. I think it's just pseudy, pretentious, and fake.
I like things to be pretty, and I value design. Both concepts are linked, but they ain't the same thing. Minimal interface design is a laudable goal. If you remove complexity from the interface medium, you remove boundaries, lower overheads, and make a system that's quicker, effective, and less taxing to use. If you do this, and you succeed in doing it well enough, there's an inherent beauty to any well considered tool, that sits somewhere beyond visual proportionality and materials. All these Apple peripherals fail to deliver much of this, sometimes quite badly. I was a bit surpised that I never noticed this so directly in the ten years or so I worked with these tools. But I was already an expert user, these flaws were a couple of layers lower than I was used to looking. Admittedly, some of the mice were pretty terrible, but I have famously always been more of a keyboard man.
After a couple of months of rotating the devices, and patiently explaining that you press over here for this kind of click with this finger, and over there for the other purpose, with a different finger, and this kind of arrow is SHIFT, but that kind of arrow is CAPS LOCK, and scrolling happens this way, I caved and bought a Logitech K-400. It is battleship grey, and not particularly pretty. It uses a dongle for wireless, not bluetooth. The integrated touchpad works fine, and has two differentiated physical buttons. The SHIFT key is labelled with the word 'Shift'. It has been immediately popular, and I have not yet had to field a single question about how the keyboard or pointer works.
I've been writing a couple of things in hy again this week. What's Hy? It's a cute idea. It's a lisp that compiles? (transpiles? I never get the difference) to the Python AST. I guess the elevator pitch might be something like clojure but for python. So yeah, a rich, super stable class-tree sort of OO language, with enormous portablility and twenty-odd years of library support for everything you might want to do, but with a nice, dynamic, lispy language and a repl.
I've played with hy a little bit on and off over the years. Actually, when I was working at SMR, I actually deployed some in production. (Somehow, I doubt that's still a thing). Python is my go-to scripting language, because it's very plain, very portable, batteries included, somewhat modern, probably already installed everywhere I work. I try to use it for scripty things, rather than shell or perl or something. Lisps are my favourite programming language. I just like how it fits together. I know lots of people don't, and I'm fine with that, but I always enjoy it.
It was a fun exercise. Hy has moved on a bit since I last tried. (They seem to have removed let, and car, and cdr, and lambda which I feel funny about), but by and large it works really well.
Things I like
I like mapping over lists of things, and in straight Python this is often clumsy and leads to densely nested comprehensions
the repl shows you the pythonic syntax of the forms it evaluates, which is helpful if you know Python
emacs mode (obv)
it has lazy sequences
and multimethods!
it is fun to work in
Things I like less
Missing some olde lisp things like car/cdr/lambda
Things often expect you to be using methods on stateful objects, which gets you an OO impedance mismatch (I have the same problems in scala and clojure)
Slightly more typed than you expect, whilst not really offering you a type system. (Particularly with distinctions between lists, sequences, iterators.)
it often seems easier to imperative loop with for than map / reduce / filters, and this seems weird.
i don't feel I have any understanding about setv variable scoping.
no STM, which I think is one of the most interesting things about clojure
I don't think the error handling does restarts and conditions and things
Summary
I don't think I would choose to use it to build any complicated systems. (Typically this is true of Python as well to be fair). I'd love to see something like an idomatic web framework in it. I could imagine using it to build serverless workers over something like apex up or chalice perhaps. I should totally try that!
I am not really very good at it yet, so I doubt I'm writing optimal programs. My scripts often look like Dr. Moreau designs halfway between a python script and something more lispy. This could well improve as I understand the underlying sequence / itertools glue a bit more, I'm often routing around confusing sequenced things. I absolutely enjoy writing little scripts like this in it, and I think I maybe enjoy it more than I would if I was writing plain python. I gave some thought about why this might be and I think I figured it out.
It could just be as simple as being all about the code editing. Python, and it's whitespace delimited blocks, is fine, and super readable, but it's always slightly fiddly to edit. Some of this is my toolchain, I'm sure. There's a lot of bells and whistles you can glue over emacs for Python work, and they're pretty good, but I do always find it a slightly fiddly experience. Balanced expressions and sexprs though are obviously an absolute joy to edit in emacs, alongside an embedded inferior lisp repl, and although it's nowhere near as integrated an experience as using slime with a "real" lisp, it's closer to that than editing Python ever feels, and for me that's a significant productivity win. So I think it will stay in the toolbox.
I recommend Hy to anyone who is interested in interesting lightweight languages, especially scripting languages. Obviously it's particularly relevant to anyone who likes python or lisps, even if just as a curiosity. If you work with Python and like using emacs though, and like the sound of 'Python but with structured editing' I would strongly recommend you look at how it might integrate into your workflow.
Last week I started a new job and with a new job comes a new computer. These days, I am once again a fairly comitted desktop linux user, for my sins, and so I asked for a Lenovo ThinkPad x270. Not without trepidation, because even though I'm a fairly expert user, it's been some time since I put a linux distribution onto a modern PC-laptop flat, and more recent hardware can present some driver challenges. It all went on pretty well, nonetheless, with just a moderate amount of tweaking, and a week or so in I can report that I'm pretty delighted with it. It's a wonderfully solid and useful piece of kit, everything works. Screen, keyboard and portability are spot on, battery life is a phenomenon, and there's at least one of every kind of useful port I care about.
It's my first ThinkPad with a 'chiclet' keyboard. It's my first without a seven-row keyboard actually. I was a little bit worried about that. Keyboards are one of those things you like ThinkPads for, if you're the kind of person who likes ThinkPads, and of course I am. Actually, the keyboard is great. I think I can type faster on it than I can on my well-loved x220 model, which is basically my high-water mark for a laptop keyboard. Trackpoint is present and works as well as ever, trackpad is a huge improvement. I am not going to say that I wouldn't like the missing keys and ThinkLight back, but I'm not aggravated by their absence. After all I can use my 3l337 remapping skills to make sure I have everything I need somewhere that I can access it, and the less often used things can just go on mod key combinations and function shifts. It has the makings of a truly great keyboard if I'm honest, although I accept these things are subjective. There was just one amusing wrinkle though.
For some reason they've put the PrtSc key in where the menu key was. This seemed pretty weird, but it could be worse. At least I still have a balanced group of three modifier keys either side of the space bar. It goes LCTRLWINDOWSALTSPACE BARALTGRPRTSCRCTRL. I just modified my xkb settings very slightly to redefine PRTSC, and I was back to using my happy path of SUPERLMETALCTRLSPACE BARRCTRLRMETASUPER, and emacsing about with gay abandon. Right up to the first time I hit backward-sexp whilst cheerfully editing code, and to my astonishment my laptop immediately rebooted without any warnings. I was so stunned I immediately tried that again. Same result. I was dumbfounded for maybe sixty seconds before I figured it out.
PrtSc is an old key, although unlike many of the old dedicated PC buttons, (Scroll lock anyone?), it's managed to reinvent itself for modern generations. Typically it is used to trigger a screenshot. GNOME sets it up for that, and while I was remapping it I figured I would be able to manage just fine without a dedicated key for screenshotting. Print screen often used to share a key with another ancient button, SysReq, and System Request is a really interesting beast. Turns out, even though it's not labelled like that, the PrtSc key on my x270 was also a SysReq. And system requests are the key to this laptop narcolepsy.
System Request was a button deliberately designed to bypass as much of your software as possible, and send a hardware interrupt direct to the operating system hardware event loop. Normal keyboard handling is entirely bypassed. It's a brain probe. No matter how elaborate your interface, or hotkey macros become, you have a dedicated batphone right there on your keyboard, a zap line into the mainframe. Even in it's most locked up system crash, this is a signal that could still get through.
Originally, SysReq had it's own proud dedicated button. Then, as it's usage was a little bit esoteric, it became seconded to PrtSc. If you wanted to access the magic zap you still could. You just hit Alt in conjunction with PrtSc. And that happens to be the second piece of our puzzle. SysReq lingered on over there for some decades, largely entirely unused. A vestigial organ, like an appendix, or a supernumerary nipple. One of those dorky joke keys on a PC nobody understands or uses, that cool Apple systems condesncendingly wink at. Linux uses it though. Linux doesn't mind being dorky, and can always use a spare modifier key. Especially one with a hardware function.
It's called the Magic SysRq key. Linux has a special interrupt handler sat there in the kernel listening for it. You can hit Alt + SysReq and then another key, and trigger special, super low level system recovery or debugging features, such as triggering a crash dump, forcing an OOM kill, or yes, rebooting the system. And that's where I was hitting it. With my remapping in place, ALT is CTRL, PRTSC is META, so when I am editing a lisp file, and hit C-M-b to move backwards one sexp, I'm actually banging on the chord that bypasses all my software stack, and pushes a reboot lever deep in my computer's lizard brain, which it dutifully obeys. A little bit frustrating, but honestly, as soon as I figured out what must be going on, it made me chuckle out loud.
Linux being linux, it's entirely configurable of course. You can build a kernel with the feature missing, you can disable it in software, or you can configure a bitmask to define which key sequences are trapped and acted upon. I have opted to disable it for now. I would rather have my META key where I like it to be, than have an easy access debugger's powertool. Now everything is closer to perfect.
This old blog post about the contrasting approaches to programming to solve a particular problem shot past my RSS reader recently. It's a lovely read about a dialogue-by-article that occured between Donald Knuth and Doug McIlroy, as guest columnists in Communications of the ACM back in the day.
The post is short, wonderfully written, and serves as something of a meta-commentary about the nature of writing about code, and how to communicate the intent and the implementation of a computer program by way of documenting it. It has a wonderful flavour of a parable from the ages, because it's re-telling a story of how the giants from the old days solved a problem in a witty and entertaining way.
You could easily read this as a clash of ancient demigods with the victor being the last man standing, but I think that's probably a mistake. 'What problem are you trying to solve?' is one of my favourite pat-rules about program design, and I don't think the two authors here are trying to solve exactly the same problem.
What problem is literate programming trying to solve? Did it solve it? Are there any better ways to solve that? Wasn't UNIX designed for use in interactive text-processing?
It makes me think about man vs horse races . What problem are they trying to solve?
I finally wired up micro.blogs! I have a micro blog. I'm not really sure what it is for but it's there. I like it anyway, because it's called cms. In order to get it working, I had to make RSS work slightly better than 'barely', and so now I have an RSS 2.0 feed. The 00's are back! It's all about microformats and POSSE and syndication and decentralization, and taking back the web.
I appreciate it's an outside chance, but should you have a micro.blog account you can follow me on there, and reply back, and be friends, and stuff. Should you not have a micro.blog account, but think you might like one, HMU, I probably have some invites or something The indie web can never die!
One of those things I generally expect to be part of the routine of running a linux desktop is a certain amount of manual effort necessary to keep things running smoothly. Sometimes this is the classic multi-decade horror story of "sound card" configuration. Sometimes its the inevitable friction between under-specified hardware and volunteer-maintained drivers. Sometimes it's the CADT principle, where everything changes around you, just because it can, as part of the generational cycle of collaborative software development. Sometimes it's just the self-induced consequence of having a system where you can tweak and configure everything to work however you'd like it to, and therefore you choose to, and sometimes that's quite a deep rabbit hole. This tale covers a small handful of these categories, although it's primarily a consequence of that lattermost case.
Mod life
Mod keys. Modifier keys, that is. Those would be the keys you hold down alongside other keys to change their behaviour. The most obvious and venerable of these is SHIFT. Hold that down and type an alpha-numeric key, and you generate a different character. With the alphabetical keys, you GET THE CAPITAL LETTER FORM. Other keys, like the numerals, get you punctuation. You may also be aware of the Alt/AltGr modifier keys, which hang around on most keyboards, and generally allow access to a different shift level, further symbols and accented characters. And then there's control, or CTRL. Maybe you know that guy as the menu-shortcut accelerator key, or maybe for a couple of shortcuts you might use in the shell, if you're a shell user. Actually the kids all call it 'terminal' these days, because that's what Apple does. And then they all use iTerm anyway, for I don't know why really but I'm sure it's great. Anyway, calm down Mac-loving readers, this story is about how terrible linux is, you're all wonderful. So CTRL in the shell - CTRL + C cancels things, CTRL + D ends a session. CTRL + A takes you to the start of the line. CTRL + E takes you back to the end. Assuming you're using a fairly standard bash shell. Those last two are slightly more interesting, and immensely relevant to this story.
Enter Emacs
They're readline bindings. Readline is a GNU library used to make command line shell editing a little more interactive. And because bash is the GNU shell, it uses readline by default. Those keybindings are the default readline bindings, and they work the same in any application that uses readline. Typically this means other interactive shells. These keybindings are taken from Emacs. Emacs is a text editor, that is to say it's an application for interactively working on so-called 'plain text' files. Not that's there's any such thing as a plain text file. Emacs is one of the most ancient, convoluted, complex, crufty, awkward pieces of software you're ever likely to encounter. It's one of the original fundamental components of the GNU system. You might say it was the standard editor. Emacs is also one of my all-time favourite things. So those readline keybindings we were discussing, are intended to bring some of the more capable text editing commands from the GNU text editor across to the GNU shell, making use of modifier keys. Emacs really really likes modifier keys.
Because Emacs is a very old piece of software, it's design was heavily influenced by the keyboards typically used on the systems of its time. Computer use was a lot more text and command oriented, and the large, pre-PC era keyboards tended to reflect this by having a large amount of mod keys and function keys available. Commonly cited examples are the MIT or symbolics lisp machine 'space cadet' keyboards, and the Knight keyboard. As a consequence of this emacs can understand a lot of different modifier keys, and has a UI that is organised around layering functionality onto different keyboard 'chord' operations. You really need at least two distinct mod keys as a bare minimum to get emacs to do anything useful at all. We already met CTRL a couple of paragraphs back, but you also need another key called META. Emacs uses them in fundamental, and interestingly composable ways. For example, you can move the cursor forward one position by typing CTRL + F, but you can move the cursor one word forward by typing META + F. It's powerful, and sort of intuitive once you understand the fundamentals quite well. Unfortunately, they mostly stopped making keyboards with META keys on them some while back.
Welcoming the X Window System to the fray
Now I am getting quite old, but I'm not ancient enough to have run emacs on pre-Internet era hardware. I did use it a little bit on 7-bit serial terminals, and limped along using ESC as a prefix modifier, like a farmer, but by the time I started really learning how to use emacs to any serious degree, I'd made the jump to UNIX machines using X11 as a graphical user terminal. Some of the UNIX workstations had a META key. Some of them didn't, but had a few other modifier keys. Increasingly, UNIX graphical workstation started to mean 'Linux and XFree86 on PC hardware'. Now IBM-derived PC keyboards don't have a META key and never did. The original PC keyboards didn't really offer many modifier keys, but by this time period, everything had mostly standardised on the 101/102 key IBM extended model archetype. This doesn't have META keys, but it does have a pair of prominent ALT modifier keys. And so, we begin to remap.
X11 is maybe one of the canonical reference points for design by committee. Fully intended to offer a portable graphical , networked user interface across a variety of dissimilar UNIX systems, it tries very hard to offer the broadest possible set of abstractions across similar base behaviours, trying to build a unifying API in all aspects. Screen dimensions and orientation, color model and layout, pointers, input devices, key-types, you name it. So you can usually configure your equipment in a bewildering, verging on frustratingly flexible manner. X11 is a very broad church and welcomes all kinds of keyboards. X11 allows you a whole byte for modifier keys (I think), so you can have Shift, Lock , Control, and then five others called Mod1 through Mod5. You can freely map key codes onto key symbols, and then assign key symbols to one or more modifiers. So obviously this all took fourteen hours to decipher in the first instance, but I gradually became reasonably adept at using the Xmodmap utility to set ALT to be both ALT and META, CAPSLK to be another CTRL and life was mostly good. You'd tweak your .Xmodmaprc file every time your keyboard changed significantly, load it in as part of your login, and everything would work. PC-104/105 keyboards came along, with windows keys, and this meant that you could perhaps add a SUPER or even a HYPER key, and bind those to other emacs macros. The system was working, and everyone got rich on the proceeds! Or not. Nonetheless, although linux desktop software was fairly terrible, it was a fine environment for running Emacs, and running Emacs was where most of the work got done after all.
A detour into Macintosh
Times have changed however, and systems have changed, and uses have changed, and so have I. Like everyone else, I started using laptops more. Modifier keys started getting scarce again, as the machines shrank down to be portable, and interfaces just grew ever more graphical. For about a decade, I used Macintosh systems, which represent their own series of keyboard configuration challenges. Macs are actually pretty good for modifiers, if I'm being fair - they have their own dedicated command key for all the system key shortcuts, and so you're free to map control and option as you see fit to control and meta. They even give you a little GUI configurator for managing and assigning modifier keys, which is way more convenient than spending hours searching for information about xmodmap. The main suckitude is that they don't have a symmetrical set of them on their laptop keyboards. You don't get a right hand CTRL. Symmetry is important for healthy typing habits with key chords, because it's vastly better for your hands if you use both of them for combinations. So you ideally want to be able to hold down CTRLMETASUPER or some combination of them with one hand whilst you type the activation keys. So CTRL + C is best expressed as a right hand finger holding CTRL, whilst your left middle finger taps the C. So my life as a Macintosh Emacs user was constantly blighted by crazy-ass schemes to find keyboard layouts that allowed unstressful ways to type CTRL key combinations.
Desktop Linux in the present day
For the last few years though, I've been back on the linux horse (and why is a different story, for another day), and my main laptop, a battered lenovo ThinkPad, has a full set of three modifiers either side of the space bar, where they were intended to go. The Debian GNOME 3 desktop is configured to use the windows and menu keys for desktop commands, and the ALTGR key, which I have on the right, as some kind of compose prefix. Even thought it's X.org now, not XFree86, and Xmodmap is heavily deprecated in favour of the XKeyboard and Xinput extensions, using the GNOME configurator and then some of my old Xmodmap ways, I could make this go away, and map ALTGR to a right meta, ALT to a left meta and the windows and menu key to SUPER and HYPER. The lenovo x220 I use has a particularly excellent keyboard and all was right in the world.
And then GNOME 3.22 switched to Wayland as a display server, rather than X. And this year's Debian defaulted to this. Even though there is an X11 compatibility layer, GTK+ and GNOME on Wayland do not talk to X11 directly for mediated key events any more, and this meant that Xmodmap can't be used to universally set modifier maps. GNOME 3 on wayland will still use xkb for key configurations, and this meant another fourteen hours of fiddling about in order to come up with a keyboard scheme that works for both GNOME and legacy X using the XKeyboard extension (XKB). This was not made any easier by the fact that all the attempts to search for information on this get bogged down in legacy explanations about Xmodmap or how to enable XKB for X11. But I got there in the end
It seems like there's not actually any supported, or easily documented way to load user configurations into GNOME 3 + Wayland's XKB environment, so I ended up slightly disappointedly hacking them into the system options files. Of course this meant that several months after I did this, a system upgrade overwrote all of my changes, and I was left without a keyboard, and a scant recollection of how I ever did it, or what any of the bits were even called.
Finally I fix it
So this morning I figured out how to assemble it all again from first principles. To make it more worth my while, this time I decided to transpose all of the mod keys as I went, so I can have CTRL on the inside of META as it was originally intended to be, and push the other modifiers to the outside edge. To save myself the bother the next time this breaks underneath me, I thought I'd write down the exact sequences here. I am not going to try and attempt to explain XKB here. There are a several documents on the web that do that job, to varying degrees of success. I'm not going to pretend that I understand how it all works, I just experimented with xsetkbmap and xkbcomp under an X11 desktop until I understood how to express what I needed to work under Wayland. Here are the steps.
System-wide keyboard configuration is fine for configuring the basic keyboard layout - using the Debian keyboard configurator, I can pick either a ThinkPad or a pc-105 model with a gb layout. The modifier layout can then be selected using xkboptions. I can tell GNOME what XKB options to apply from its database, using the dconf configuration key /org/gnome/desktop/input-sources/xkb-options.
If you're playing along at home, you may have spotted that cmswin is not the name of any valid xkb layout. The wrinkle is that none of the built-in options offer quite the right set of combinations. So this is how I added my own custom XKB option.
1: Define an option
I added a new file usr/share/X11/xkb/symbols/cmswin to define my partial keymap.
Further to this, I modified /usr/share/X11/xkb/rules/evdev
adding the line
cmswin:cms_modkeys = +cmswin(cms_modkeys)
to the section
! option = symbols
I believe this is adding an option named cmswin:cms_modkeys to the dataset assigning it to parsing the 'cms_modkeys' entry from the 'cmswin' file, in the symbols subdirectory. The convention in xkb is to name all the different symbols using the same substrings, and it's terribly confusing when you're trying to remember which part does what, although slightly helpful when you're trying to perform the reverse map and locate which file is responsible for which option, I suppose.
3: Make it available for GNOME
The final step is to add the line
cmswin:cms_modkeys fix keys for emacs
into the file /usr/share/X11/xkb/rules/evdev.lst
I think this does something like import the option into the environment. There is also an evdev.xml file in the rules directory, which looks like it marks up the options to be used by the GNOME gui, but I didn't bother with that one, because life is too short to hand write XML for computers to parse, and I'd already spent half a day setting this all up. To give you an idea of how tedious this all was, for a while I'd added the evdev option into the section marked !option = types rather than symbols, and this caused wayland to stick to a crash loop as soon as I loaded the XKB option into the dconf key (with no visible error logs! yum!)
4: Retire, rich from the proceeds
With all of this in place however, everything works fine. For now. GNOME seems to be in a bit of a transitory phase with regards to keyboard and input configuration, it looks like they're reworking everything to use IBUS in the long term, so I expect I'll be doing some form of this dance again within a year. Until then though, this document can serve as a reference for the next time I, or anyone else interested enough needs to figure out how to do this.
2017 then, and nothing seems to have really changed that much at all. Desktop Linux is still terrible, and desktop linux is still awesome. Emacs is still terrible, and Emacs is still the best tool I have.
I've been very gradually upgrading this site back to life for a few years now. Very gradually #amirite . However, after earlier this year having found myself accidentally on the front page of Reddit, HN etc. with my post about building the IMDb boards , I found myself slightly embarrassed, not only by the amount of attention ( 40k+ uniques in the first two days, holy shit! ), but also by people pointing out how clunky the site is to read. Often several times a day.
The styling on the blog section, much like the rest of the blog section, wasn't in a terribly well developed state of completion. I just threw together some hand-written CSS to approximate the look and colours of my last existing Wordpress theme, which I had been fairly happy with. Now that theme was set up maybe ten years ago, and my initial port over to this 'new', self-build CMS maybe four or five years old itself, and I had given no thought at all to mobile, or in fact any screen device very much different from my own laptop display. And my main laptop display is a 1024x768 pixel non- IPS Lenovo ThinkPad x220. That is probably a significantly worse screen than your phone has.
In 2017 it's pretty stupid to build web pages just to be viewed by desktop browsers, so today I'm pushing out a rebuild of the display layer and theme, that hopefully works a little more responsively across varied devices. It should also be easier for me to evolve. I hope it improves things for my handful of select readers. I'm not terrifically good at front-ending, and my heart isn't often in it, but I have tried my best.
I'd like to be updating this site more frequently again, he writes, like one of those bloggers apologising for never blogging , but a large part of getting any kind of schedule working there, is streamlining the publishing workflow. To that end, as well as a more modernised front-end and theme, today I've also released a new site deployment system, that allows me to update the site software more easily. This is clunky, but at least automated. Previously everything was just checked out into a home directory, hand compiled and run on the server. Now that's mostly still happening , but now it's all scripted with configuration management tools so I can release updates like this without having to remember exactly how to set it all up again by hand from first principles.
Of course, for writing articles, I'm still shelling into the server and hand writing html files like a farmer , but it's all steps in the right direction. Sometimes I don't shell in to the server, I author the posts directly using emacs tramp-mode which practically counts as using a GUI round here.
Some time on Friday, IMDb announced that they intended to shut down their message board system, permanently. I don't find this to be a particularly surprising decision. I'm more surprised that the message boards are still there, in 2017, seemingly essentially unchanged for the last fifteen or so years. They've had a few coats of paint, and a handful of feature improvements, but they largely seem to be backed by the same system design developed by the in-house tech team, way back at the dawn of the century. And for the bulk of that early development time, I was the primary developer. As it has said on my homepage for many years, 'you can blame me for the message boards'.
A long time ago in a galaxy far, far away
I was incredibly excited to be asked to join the IMDb developer team at the end of 2001. Aged 30, with almost a decade of professional software development under my belt already. Although 2001 sounds today like it was the relative stone-age of the modern web, which of course in many ways it was. At this point I had already spent several years working on basic web applications in the original dot-com boom, and I was in-awe of the IMDb , which even back then was a somewhat venerable internet institution. Founded in 1990, it thus predates the invention of the World Wide Web by several years, having started out as lists of data shared via USENET posts. At the time I joined, they were a couple of years into their Amazon ownership, and starting to expand the team.
As I started, they were just on the cusp of launching IMDbPro and had an ambitious roadmap to completely rebuild the main website from the inside out, using the shiny new technology stack the small development team had built from the ground up to power the IMDbPro application server. This, I thought was a very clever hack - imdb.com was a hugely popular website, and this approach of adding industry focused features to a subscription remix of the site built on top of the same data feeds (still basically formatted text lists, using the conventions of the old USENET based tools) meant that in effect we could use the far smaller user base of the pro site as a test-bed for the new tech, and gradually port sections of this across to the terrifyingly high volume 'consumer' site, without having to do a rewrite and a relaunch. To further sweeten the deal, if you look at this arrangement, this meant that the test-bed users would actually be paying to break in the newer software, and helping you iron out the bugs.
In 2001, a shiny new high performance web stack meant perl . Apache 1.3.x running mod_perl to be more precise. In case you don't know what mod_perl is, it's a piece of semi-deranged brilliance that wraps the perl language interpreter into an apache module as a persistent runtime and exposes the internal API of the HTTP server to it. This lets you write applications that are now effectively themselves apache webservers, with direct access to every part of the HTTP serving lifecycle. Furthermore, by using the other neat hack, Registry.pm you could use modules or scripts that had been designed to work as CGI scripts, and get the some of the same speed boosts, unmodified. With these techniques, you could write perl applications that went almost as fast as Apache could, and in the late 90s/early 00s it was this or PHP. PHP back then was pretty grotty, I thought, and the cool kids were all using perl. Perl had libraries, and excelled at gluing existing bits of UNIX together. This meant you had to write far less of the application by hand. Yup, by hand . Let me dig into that a little bit
It's the pictures that got small
Writing web software back then was a fairly different prospect. In my circles, we didn't really have much in the way of frameworks. There were a few enterpris-ey things floating around that converted your big IBM and Oracle and Microsoft client/server application into some kind of terrible intranet suite that required ActiveX support to load any pages, and I'd poked around with Zope with some interest, but by and large if you were doing anything interesting, you used FreeBSD, or linux (2.2, with SMP support!).
You'd most likely use Apache 1.3, forking, and write your site as a combination of static pages, server side templating and CGI exec-d programs, in some kind of UNIX scripting language (usually perl, but any of the usual suspects were relatively common, including actual honest-to-god shell scripts), or maybe you'd write a performance critical CGI as binary in C.
For data processing, you might connect your application directly to a pre-existing company RDBMs, if you had such a thing and your DBA, if you had such a thing, let you, or you might deploy a SQL db on or nearby to your web host - usually MySQL 3.22 with ISAM and a quasi-religious intolerance for foreign key support but that was OK you could do all the data validation in application code. ( A bit like JavaScript databases in 2017 )
We had libraries for common tasks, like parsing wire protocols and file formats, and wrapping utilities to do things like generate or resize graphics, but you'd stitch a selection of these together in an ad-hoc fashion to make a 'system'. A typical web stack would be table-based HTML with attribute styling and inlined images for typography and spacing , possibly pre-rendered, but maybe dynamically generated, then some CGI scripts for user management full of hand coded cookie and session tracking. A relational database for persistence, using hand coded SQL and a custom database schema. Page generation via a self-written templating system, gluing skeletons of layout-oriented HTML around variable interpolation with inline conditionals. This part would often run as server-side includes, but sometimes this would also have just been handled by CGI scripts.
Maybe you'd have a hand built filesystem cache in front of this. 'Front-end' back then would often build static page representations, first in Photoshop or Illustrator , which would then be converted into single HTML page masters in Dreamweaver or FrontPage and then handed over to the back-end coders to clean up and crack apart into templated fragments, by hand. Single byte string encodings through-out, no threading, a light veneer of Object Orientation over internal data structures - you'd have a small cluster of actual physical servers, perhaps in a data center, but often on-premises, sometimes in racks, sometimes actual tower servers in the corner, directly connected to an internet router of some pitiful capacity. Sometimes your cluster was as small as one machine.
Architecturally you'd have a webserver, perhaps two if you wanted to split 'heavy' dynamic serving from lighter or static content. Your database might end up on its own box with better IO and networking. If you had enough web servers you might put some kind of load balancer in front, perhaps a HTTP reverse proxy as an accelerator cache (often another Apache, sometimes Squid ). In 2001 I'm not sure I fully understood what a CDN even was . You'd deploy with FTP or maybe rsync , sometimes the production filesystems were locally mounted via NFS or SMB and you'd just copy stuff over, or edit it in place. Version control, if you even had any might just be renaming files, perhaps SCCS or RCS. Advanced users might have CVS. Designers might have a pre-OS X Macintosh , suits would use Windows , developers had something more of a free-for-all - windows 2k , desktop linux , I used BeOS for several years whilst that was still a thing, and seemingly everybody , but everybody used emacs to write code - GNU emacs was common, but the cool kids were using XEmacs . Sometimes a remote XEmacs client on your deploy host attached to your local X11 server over the wire . Crazy days.
My God, it's full of stars
So that's the scene in 2001 when I joined the amazon.com family as an SDE , working on the new IMDb platform. I was a fairly hot perl programmer, having spent a good few years designing and rewriting custom web 'frameworks' and optimising mod_perl architectures. I was really good at SQL, at least I thought I was in comparison to most of my peers, and I had developed a particular fondness for the then slightly uncommon PostgreSQL database engine . I'd done quite a few web things - early corporate intranet portals, hobby sites , moderately popular dot-com publishing houses , but this was a step change into an entirely bigger league.
In reality, especially as I look back with hindsight, I can see I had very little idea what I was doing, but hardly anyone did. There wasn't a lot of published material on architecture - everyone read Greenspun , but there was nothing like the modern tech web, scalability porn, conference circuit. No HN , no Reddit , no twitter , no Facebook, and looking things up on StackOverflow was still almost a decade away. It wasn't even that easy to find what scant information there was, you have to remember that Google was barely yet a thing. Information sharing tended to happen on mailing lists, using actual email, or maybe still on USENET. ( Paul Graham hadn't yet written ' A plan for spam ', and we didn't really have functional automated spam filtering).
IMDb had an unusual working setup for the day, as befitted it's birth from a federation of USENET correspondents. Everyone worked completely remotely, scattered around the world. At the time I joined, there was an express preference for staff who could attend a weekly company meeting over lunch, near Bristol ( in a cafeteria, attached to a swimming pool ), and the majority of the tech team building the software was now based around this area. Home Internet connectivity was still largely 56kbps or lower dial-up , possibly metered, although I was lucky enough to be in a part of Bristol eligible for an insanely fast 1Mbps cable connection .
Anticipating having to work on significant amounts of DP, potentially offline, I asked if I could be provided with a small server with SMP and RAID capacity, and was rather surprised by a small tower HP Proliant rig turning up at my house, cocooned onto a loading pallet too big to fit through the front door. I had to unglue it piece by piece and carry it up to my 'home office', a box bedroom full of IKEA tables, slightly too tall to be comfortable desks, and assemble it in place. I christened it mavis.imdb.com, and installed Debian stable on it, which involved most of a day figuring out the hardware RAID drivers, and from that point on it's shrieking fans and disks were a constant part of my daily life for the next half-decade. Eventually a house move allowed me to get it into a makeshift server cupboard where I could deaden this persistent din behind a door and blankets and curtains. I occasionally wonder now, in my middle-age, if I have a frequency gap in my hearing to match that particular pitch, but if so, it's not affected me enough to care to get it measured. As the noise tended to interfere with music, for the first few years I developed a habit of listening to BBC Radio 4 morning to midnight, and therefore, when there wasn't a test match to listen to, for a brief period of my life I developed an unusual degree of expertise in the comings and goings of 'The Archers' .
One consequence of the remote working, and patchy connectivity was that the development work in the tech team was informally silo-ed up into sub-systems that individual engineers had ownership over. The very first task I worked on, after getting a working build of the entire stack onto mavis, was porting the statistics page across to the new web stack (internally known as 'mayhem', after project mayhem , everyone was big on movie references, naturally) by way of familiarising myself with the application and infrastructure. I made a perfunctory stab at that, and then I was searching around for something more substantial to own. The forums, or 'message boards' seemed to be a natural candidate.
The most recent piece of work I'd done at my previous gig , had been to contribute a threaded discussion system to our general purpose content management system, which allowed a tree of conversations to be attached to any content id in the catalogue, so the site users could have a threaded comments section attached to any content. This had worked pretty out well. By contrast, IMDb had a pretty threadbare generic forum system, a standalone phpbb installation, almost entirely isolated from the rest of the system, organised into a few dozen general purpose with I think even a separate login system.
A business goal for the next year was to drive up user registrations, and the forums system seemed like a good feature to assist with this. It offered additional site value that was only viable to registered users. Another target was to integrate the boards system more directly into the movie database, allowing people to have conversations directly attached to the pages for movies and shows. Another important requirement was to allow for a system that would let the data contributors directly communicate with the data management team. So I was tasked to do something with the forums to meet these broad goals, and the implementation and design of it was largely up to me, informed by regular feedback from the wider team onto weekly progress reports and via the team lunch meeting.
We're going to need a bigger boat
I considered a number of approaches.
I could have extended the PHP forum system as was, to support the new features, but I didn't really consider that for more than a couple of minutes - it was PHP, which I didn't know terribly well, and disliked, and would be harder to tightly integrate with the rest of the mayhem app, which was a domain optimised mod_perl web service.
I wondered about wrapping a USENET service, which had a lot of appeal, in as much as a lot of the base mechanics of hierarchy would be already covered, and a highly scalable architecture with a portable standard with several existing back-end implementations. I really liked this idea a lot, but I rejected it eventually when I realised that it would be difficult to build an integrated web front end that offered as much functionality as a stand-alone newsreader. If I had been able to find a decent open-source web NNTP client I might very well have done this.
Another alternative would have been to find an alternative forum system that was more amenable to customisation. I considered using the slash system that powered slashdot.org, but I rejected that because at that time it had a reputation for poor performance and uptime, and was struggling with coping with trolls. I really should have paid more attention to these ideas , both of which would come back to haunt me
eventually using a mixture of naivety, hubris, ego, enthusiasm and pragmatism I decided I'd build something custom, scaling up over the ideas I'd used for the comments module in my previous job.
The basis for that system was something I was quite proud of, and in some senses it was quite a clever hack. We had wanted threaded discussions, but it's famously tricky to model trees in SQL. My first attempt, with hydrating flat lists into trees at runtime from a SQL result set was computationally a little bit expensive for the hardware of the time, and slowed up page rendering in the articles with comments.
So I came up with an ingenious scheme. I'd store several sort fields against the comment records - one representing the vertical position in the thread, and one representing the indentation level, and every time a reply was inserted into a comment thread, I'd compute the correct indent level by adding one to the parent reply, set the vertical position to one larger than the parent, and then update every larger sort sequence to increment it by one; so that they were sequentially stored in thread order when read by that index. As I was storing the timestamp, and a sequential post id, I thereby had a system that could trivially read back conversations by order of time, order of posting or order of reply. This meant that posting was relatively computationally expensive, but only on the database server, whereas reading was simple and fast. I reasoned that reads were many times more frequent than writes, and biasing the system this way would optimise it for the common case, and avoid the need to build a cache invalidation system .
This system actually had worked out pretty well in practice, at least for Accounting Web comments sections. Although it's conceptually neat, it's also actually pretty fucking dumb for a couple of reasons.
this system means that adding comments becomes linearly more expensive as threads grow in size. The more popular a system gets, the work needed to post an individual comment increases in a polynomial fashion
Oops.
I wasn't entirely stupid, I had calculated this downside, and I'd done some scaling calculations on paper to see what the cost of implementing this for the IMDb would be, and here I made my first actually stupid mistake, I used the metrics of the existing forum system to try and predict the capacity of the new one. I can't remember the exact numbers now, and I've long misplaced the notebooks, but it was something lower than a thousand posts a day, and the average thread length was a few dozen posts. Amazon could afford a useful database server, and it seemed like I easily had a couple of orders of magnitude of headroom. Telling myself that premature optimisation was the root of all evil , and conveniently ignoring the fact that this design was literally entirely borne of an optimisation hack, I decided to proceed with this scheme.
Show me all the blueprints
I gave the design a lot of thought. I had been a USENET user back in the glory days before spam and binaries had rendered it toxically uninhabitable. I adored slashdot. I'd used a lot of shitty web forums since then, and I had designed a flexible engine that could handle any kind of post based discussion grouping. I thought this was a great opportunity to design a discussion system that I'd want to use myself. scratch your own itch . I think I already mentioned, I didn't really have much idea what I was getting myself into. Ah, youth.
I thought that most of the grief and spam I'd seen in other systems, was primarily because of the cheapness and disposability of user identity. I figured we could tie that down by disallowing anonymous posts, which was aligned with the goal of increasing user registrations already - maybe ultimately we could link them into amazon.com accounts, and therefore real identities. I wanted to give the users the ability to personalise and curate their site home page, so they'd have an investment in a community they valued, and would be publicly accountable to.
Another thing I'd noted about other forums was how quickly they stagnated into a dominant clique, and deterred new joiners. I decided this was in part because of the permanent record; the conversations got stale because everything had already been said, and the groups then tended to be dominated by handfuls of high-status members with visible post-history. Groupthink dominates, outsiders are shunned, filter-bubbles prevail. I thought that an interesting solution to this would be to actively expire user posts. IMDb already had a system of user reviews for more static user content attached to database entries. The boards were for conversation - so we'd just periodically remove older content, and make no secret about it. This should stop the entropy lock-down, and also give us a mechanism to keep a lid on the database / thread size to help with performance. Everything should stay fresh and sparkling and self-rejuvenate.
I know lots of this was naive thinking and with 2017 hindsight, it's easy to see the flaws. In 2001 though, there was much less experience of online community management. We thought we knew about trolling, because we'd experienced previous communities, but I don't think anyone yet had a handle on the scale and the scope of it in a significantly mass-medium consumer Internet.
I really wanted nested threading, which is a very good, perhaps too good, way to promote reply-oriented posting and reading. For that same reason, I didn't want threading to be the implied default mode, because I thought it promoted point-by-point refutation, which lead to arguments and flame-wars. So I envisioned a system that could seamlessly move between a flat or a nested view, with a cookie to fix it to your individual preference.
Each post would have two actions - a new top level post in the thread, or a reply to the particular post, and the different view options would allow you to see how the thread timeline fitted together from each point of view. I felt this would encourage replies, without mandating them as the only form of discourse. This meant that the organisational system was topic ( either a generic, or a database object ) , consisting of a thread - which was defined by the opening post made by any user at the topic level. This then collected numerous replies, which themselves could have sub-threads of reply.
Mindful of the fact that this was still an era of expensive and slow dial-up and low end computers, I wanted the ability to view in narrow or expanded views. I didn't want to force people to download gigantic pages of browser and modem-choking deeply-nested table layouts, so we would flip between outline and expanded views as well as flat or nested. I wanted people to have a static, but customisable home page that they could add content, style and flair to; hoping to give them a sense of curation and ownership and identity, that should help act as a brake on too much antisocial or negative behaviour. I'm not sure I was even smart enough to wonder if people would use their home page to host offensive content. (Of course, some did).
So I started to build it. Initially it went really well. On the data model and storage engine side of things, I was on a pretty solid footing, it was familiar ground. I carried on using PostgreSQL, and we specified a decent (for the times) server to host it on. No H/A or replication at all. I'm shocked at that idea now, but at the time I had reasoned that we were building an ancillary, purposefully ephemeral side-car discussion system with a different storage layer to the main site, and we'd be fine with regular hot backups - in the case of disaster we could shut them down without affecting the main site, and restore from backup. In the case of total and utter catastrophe, we could just reset them to zero and start again, they weren't designed for permanence anyway. Feedback about the design and features from the rest of the team was positive, with plenty of enhancements and suggested tweaks, and the system started to take shape.
The UX layer was way harder than I'd anticipated, and because of this, I started to get a bit bogged down in the 'second 90%' of the first deliverable. The mayhem engine that the team had built (a really clever piece of software design, that I don't really have time to give justice to here) had never yet really had to cater to highly dynamic pages - it's core purpose was to serve flexible views of an almost read-only statically compiled dataset of movies and people. It was originally built around doing that in a particularly optimised way.
I had to build up my own HTTP POST and form handling layers that would integrate with the existing HTTP handlers, from a somewhat lower starting point than I was used to doing, and this soaked up quite a bit of testing and debugging time. Even worse was the display code. We didn't really have much facility for dynamic page layout in the templating system - which was both highly customised, and complex; the site page templates were used to drive the static build system, via a custom compiler - the markup in the template specified what data views would be generated by the build, which directed the data builders that compiled the binary movie database- the pages were effectively just compiled to a stub handler for a specific route which would seek to the object index in a particular data index, and then basically sprintf the data out port 80 as a hydrated web page. This was a fast way to serve varying pages with identical structure, but not immediately well suited to highly adaptive constantly updated live pages or submission forms. Still, I wanted the boards system in the existing stack as well as I could manage, and so I laboured to build the missing features into my system in a way that could integrate well, which involved at least one complete abandoning and rewriting of the internal API.
The actual boards display templates themselves were a significant time soak. We had a great designer, who took my ugly box tables prototype output, and turned out nice looking blueprint designs for all the various view modes and forms as static web pages. This was of course the era of the browser wars, and we were expected to support a bewildering array of user agents from the Netscape 3.x era onward, inclusive of weird-ass things like AOL clients and MSN web-tv set top boxes and goodness knows what else...
Busting these intricate table-based views apart and back together again into a cryptic markup and logic language, adding the various ( session global ) mode flags such that all the different view combinations rendered as functional pages that degraded gracefully took me weeks . I was slipping past shipping dates and entering a terrible crunch death-march to just try and get something out of the door. Unhelpfully, this was all happening at a time when I was having a few strains in my family life, and also struggling a little bit to balance this into a sensible routine of working from home, I was ping-ponging between getting distracted away from 9-5 and then overcompensating by working across nights and weekends. Eventually we had to pull out features to ship.
I drastically cut back the home page customisation, abandoned all the planned but unstarted work for a search index, and only had time to add the most rudimentary admin features. I had wanted to migrate the existing posts across to the new system, but I'd not even begun to start on that, and that also hit the cutting room floor. With a lot of assistance from the rest of the tech team to get it over the line, we hit publish on the initial TNG boards system some time in the summer of 2002, later than planned by some months. This pattern of the message boards being more work than expected for all parties that touched them would be the prevailing tone for the next several years.
A test designed to provoke an emotional response
User feedback was immediately negative, and highly vocal. Lobbying started instantly for the reinstating of the previous system. People complained about the new designs, the complexity of the new display options, the inevitable launch bugs. I was silly enough to join in the conversation to help explain the launch and solicit feedback, and from that point on I had an onslaught of direct contact messages and emails, occasionally positive and friendly, but more often than not weird and offensive, sometimes abusive. You do try to tell yourself that you can just ignore the trolls, but in truth it is quite difficult to remain completely unaffected by emails that compare you to a child rapist and calling for your death in offensive terms, even if it was only provoked by you breaking a font size in a particular version of Internet Explorer 3 . You never quite get used to that, I find. I was pretty crestfallen with all the negativity after all that work, although the team were positive and assured me that some of the board users could be like that, and that in general people are more vocal when they're complaining, and are naturally somewhat resistant to change. I still felt pretty down.
My mood did soon change after a few weeks. The new boards were kind of a hit. Maybe a smash hit . They quickly overshot my scribbled calculations of scale in a slightly worrying manner. With some judicious database tuning, the performance stayed OK though. For now. Then we added links from every title page (IMDb pages were sub-grouped into title pages, for tv shows and movies identified by a key called a tconst which looked like tt1234567 and name pages, for people, robots, animals etc. from cast and crew which were identified by a key called an nconst which look like nm1234567 ; top level boards un-linked to other database objects therefore got a new key type called a bdconst , somewhat inconsistently, these looked like bd1234567 and didn't matter very much because there was only ever a few dozen standalone boards) and the numbers started to properly hockey stick .
At the time we used to compute the page views in a weekly report which broke out the top N subsections according to first level directory. We never shared traffic numbers publicly, and so even after all this time I will be respectfully coy, but the highest chart topping positions were obviously things like /title, /name, /search /news /chart etc. At launch, the boards were lurking down the bottom, nowhere to be seen, but after we started the title conversations they were solidly into the top five, where they remained with ever-accumulating numbers, and user registrations clocking up correspondingly.
From that point on, I spent a significant amount of my waking life 'doing the boards' for the next several years. Initially I was scrambling to put in the missing features we'd pulled before launch - post editing, markup for posts and then profiles in a hand-rolled version of BBCode ; again with a stupid insistence on display time optimisation, I converted this to HTML at write time, which meant that when we added post editing, I had to backward parse the HTML back into bbcode to be re-edited, all with a misconceived series of chained regular expressions . This lead to an endless sea of parse bugs that pretty much guaranteed that the markup and emoji (although they weren't called that yet, we called them 'smileys') set would be once fixed effectively sealed forever, even though I'd taken the trouble to add an admin edit tool, that allowed for updates to markup to be made by non-developers through the CMS API.
I'd thrown together a naïve search API, entirely based on un-indexed SQL substringing, which I'd fully intended to replace after launch. It never worked, and the system filled up so quickly that it killed the page cache entirely by constantly table scanning the texts, so much so that I spiked it in the first week, and never got a chance to work on it's planned replacement. I was still getting emails complaining about that five years later after I'd left.
With the surging popularity, came increasing amounts of negative user behaviour, and I had to increasingly devote development time to adding abuse processing tools for our small moderation team, onto what had only ever been an afterthought of an admin system. We never proceeded to link up the user accounts to amazon accounts, and I'd never planned to add user-driven moderation. My quixotic hopes for user killfiles (renamed to 'ignore lists', which is a far better and kinder name), global killfiles (known as the ' Phantom Zone ', because I love Superman ) with account history purging and deletion weren't enough on their own, and the tooling for processing abuse reports were too clunky and slow, largely because I hadn't planned enough for them from the offset.
I was now fighting a constant war on two fronts. With the popularity of the system way beyond my original estimate of a few thousand posts a day. We quickly escalated to a point where the really popular off-topic boards were ersatz real-time chatrooms, accepting hundreds of posts a second at peak-times. All of this in a cursor-pooled synchronously blocking database directly attached to the HTTP display servers. I spent a great deal of my work time just constantly rewriting sections of it all to squeeze efficiency out of this setup. First with indexes and schema changes, then with hardware upgrades and tuned and profiled system software, then with a complete rewrite of all of the database logic to use stored procedures , and finally a long overdue table sharding so we could cluster boards between different tables and tablespaces to balance the IO and garbage loads. At the same time on the other front we were trying to come up with ways to lower the proportionally increasing cost of trolling and abuse.
My partner was temporarily stationed away in London by this point, so I was home alone, aside from the dog . Workdays at this point quite often consisted of walking 12 paces from the bedroom, still brushing my teeth at about 09:30, getting a support email, starting to poke at something interesting with the boards, and then not giving up until the small hours of the next morning. I was fairly obsessed with all of it, and my health was suffering, although I was too close to all of it to properly see this at the time. I developed a weird collection of neurological symptoms which stubbornly refused diagnosis, and subsequently appear to have been entirely stress-induced.
We still were choking out at peak load times, and it was starting to have a knock-on effect to the rest of the site. Eventually, a super-talented colleague helped me out by implementing a workable version of my poorly articulated designs for a caching database proxy; implemented seemingly overnight by him in C, it spoke postgresql wire protocol and cached result sets in a filesystem that we mounted on ramdisk. Kind of a home-brewed combination of memcached and pgbouncer . The simplicity and effectiveness of this just took my breath away, just as much the lesson that if a software thing doesn't exist, you can just make it yourself. Everything is just ones and zeroes, as I am very fond of saying to this day.
With this addition we got to a place where the system was in enough of a steady state. We implemented more banning and reporting, added a reputation score based system that slowed the rate of posting for users with lower reputation scores, which also helped reduce the saturation write loads at peak. Eventually we added an automatic moderation robot with a learning capacity and pluggable rulesets. I called him Spike . He worked fairly well, if a little bluntly at some times.
I hope I'm not giving out the impression here that it was all entirely negative. It was definitely a rollercoaster few years. Exhilarating, and also very entertaining. The boards were a living thing that had sprung out of nowhere, literally something I'd created in my spare bedroom. It sort of felt like a Pacific-Ocean sized colony of sea-monkeys eternally fizzing away with unexpected activity right there in my spare room.
Although they were often frustrating, the users were also inspiring, and creative, and surprising, and occasionally pretty funny, even some of the (gentler) trolls. On top of an understandable level of frustration and annoyance, I generally found I felt a sense of sympathy for them, and their complaints and frustrations with the system. All of this was before the age of 'social media', and I could almost feel the shape of it hanging there, slightly beyond where we were heading, off-piste and in a direction we probably shouldn't venture into.
A consistent surprise was the amount of effort people put into curating their limited patch of profile space, and how social and to us off-topic, it all was. We were constantly running into people trying to use the boards for personal social spaces - I argued for providing individual personal boards for every user at one point, but the management team explained that we weren't really in the core business of general social networking. It confused me at the time, and I had to think about it for a while, but I think that was correct thinking, and there's a lot of wisdom there. You simply can't do all possible things well. With a small team, and a big world, you benefit most from focusing entirely on the things you're best at and the things you want to be better at.
A few of the sillier trolls stand out. There was one early griefer , who we very easily IP traced to a school library, I think based in Canada. We waited until he was in mid-session one afternoon, and then if I recall correctly, management called his head teacher, who was then able to apprehend them in the act. There was another, very silly catfish troller called tabitha_cyeg , with an obviously manufactured identity. Their M.O. was posting bizarre conspiracy theories about the site technology, and myself, during which they'd claimed to have hacked into using l33t -sounding but completely irrelevant NetBIOS vulnerabilities replete with faked server logs, and on one occasion 'hacked' emails from myself revealing my true name to be something along the lines of 'Claude M. Savoire'. Quite a few users were seemingly entirely convinced, but to me it was pythonesque.
Getting contacted by the Feds to deal with users who'd been posting death threats about President Bush was weird , at least it was the first time, and I got a few PMs and emails from actual industry figures, which was always quite exciting. I personally banned a moderately famous Hollywood producer this one time, for abusive posting, which is something of a curiosity. I remember going to watch Jay and Silent Bob Strike Back at the cinema around this time frame, and getting a particular kick from the sub-plot where they individually visit all the internet forum posters who have been rude about their previous films.
I watched people fight and friend. Saw a few romances and a marriage or two emerge from the regulars. I read, and occasionally got involved, against my better judgement, in fascinating and productive conversations. I still bump into people IN REAL LIFE who reminisce about the boards and are to this day impressed with me when I tell them I had a big hand in their genesis. I once spent an evening in a darkened restaurant patio overwhelmed to tears as a kind man explained to me his young daughter, hospital-bound and dying of cancer, had used the Harry Potter IMDb boards as her main social life in her last year, and how much that had meant to him and her. Stories like that are just a profound privilege to have had even the most tangential involvement in.
And I learned so much. Working with such a smart team, on such a great and special piece of the internet. Learning about every aspect of scaling a web stack from the disk blocks up to the network and back down again. This era was still 32-bit Intel hardware, and I learned a huge amount about that, and UNIX profiling , and the linux virtual memory system and file system , and HTTP caching . I made so many mistakes, because there just wasn't any other way for me to learn, and I did figure out how to fix or improve on many of them.
I learned about PostgreSQL internals from the wire protocols all the way down to the storage models in some detail, and to this day I'm a pretty great PostgreSQL DBA , when I need to be. I learned a lot about UX influence and steering behaviour, albeit by mostly getting it wrong. I learned about building search engines, and service orientated architecture, and why you really shouldn't hang responsive systems off of blocking I/O, and maybe message queues are useful. I learned how to measure system performance all the way down to the CPU cache level . I learned how to keep focused on problems I didn't yet know how to solve, or perhaps didn't yet understand. I learned lots and lots of things about movies and cinema history, much of it just by osmosis poring over the data sources. I learned how to better manage my own time and projects, and I learned what it feels like to burn out , and what you should do about it when you know that you are. Since I left Amazon.com, I've had a great and varied career , and I think at least 75% of the useful things I know how to do well I learned first-hand on that gig, and I've always treasured, and respected that.
Always. Be. Closing.
And now they're shutting the boards down. I first heard about it via text message, oddly enough; but shortly after that it was all over my news feeds followed by a slow stream of emails, checking in. Friends, ex-colleagues, some of them from former boards users. I felt an odd sense of shock about it, in a way, and slightly emotional. Sixteen years is a ridiculously long time in Internet years. The web itself wasn't sixteen years old when I joined Amazon, and nor was the even older still IMDb. I don't use the boards myself any more, although I do occasionally look over them, perhaps once or twice a year. It's been clear for a while that they're not getting a fraction of the use that they once did, and that's fair. The web is a different thing in 2017 entirely, and that's also a good thing.
Communications technology evolves, and hopefully improves all the time. People have all kinds of social networking now for communicating, and the bulk of this is happening on different, smaller screens than anything I could have envisioned when I was first sketching out some pencil ideas in a gridded notebook. An actual Filofax I believe. It was very humbling to see the amount of twitter traffic noting the IMDb announcement, as well as the number of actual proper news sites that wrote this up as something significant. The Verge report seemed to think the IMDb message boards were era-defining. That's something, I guess. All things must pass.
There's just one more thing that's bothering me
' Mjeyds '. On the imdb board bbcode syntax, there's a particular smiley that you markup using this bizarre word. People occasionally ask what the term means, and I've always enjoyed the mystery, being one of very few people in the world to have any claim to know the answer. I guess it's now or never for the reveal.
The emoticon set was curated, uploaded and configured by my erstwhile designer colleague. He took responsibility for naming them. He wasn't English, hailing from Denmark, I believe via several other countries. When I pressed him for an explanation of 'mjeyds', he said it was supposed to be an onomatopoeic of the way the late Graham Chapman said a languorous 'yes' whilst sucking on a pipe in a scene from Monty Python's the meaning of life . If it is, I guess it works better if you're using a Danish alphabet? If you've got all this way through this post only to find out the answer to that question, then I am sorry if it is an anticlimax, but thank you for reading. Maybe some things are better left mysterious. Another lesson learned.
Crazy Credits
this is a personal web page, and an entirely personal and subjective retelling of my own experience building and maintaining a small section of IMDb.com a long time ago. Whilst I'm happy to take personal responsibility for a large amount of the boards creation and inspiration, I don't want people to get the impression that this was in any way a solo effort. All of the work outlined above was produced in the context of a small dedicated team, and although I've refrained from naming names, and attributing ideas elsewhere this is borne more from a desire not to miss anyone out - after this amount of time there's simply no way I can credit individuals for parts I can remember without failing to attribute others for equally important contributions I have forgotten. I've done my best to be honest about facts and timelines, and tried not to infer too much about third party motivations, but I know I've forgotten things and misremembered others. Working from memory, after this amount of time, such errors are only human. If you spot anything terribly wrong, or have any questions or corrections, please get in touch. I'd like to thank the entirety of the IMDb team 2001-2005 for working with me on all the aformentioned things, and more. Great team, great times
It was never entirely my intention to go offline for such an extended hiatus. Even though the web is intrinsically brittle and ephemeral, I like to do my bit to keep my little backwater serving 200 OK s to the half-dozen people who stop by to check in regularly, and the couple of dozen who linked to something I put up at some point. It's basic web-citizenship as far as I'm concerned.
Before we went fully dark, I'd not posted for a long time already . And before that I'd slowed my posting down to something of a crawl. I think there's a few reasons for that. It's easy to get bored with blogging for the sake of blogging, especially in our current age where everyone shares profligately across many social platforms . It's fairly common to see blogs that have fallen into a recursion of no posts for months, then a post apologising about that, and then further disuse. I don't think this is one of those, but the proof is in the posting I suppose.
There's certainly been less time in real life for auxilliary pursuits like online rambling, and that's a big part of the reason. No time for any proper content posts, concomitant with a surge of alternative social platforms to play around with, meant it often seemed a bit redundant to post arrays of short-links , when I could just throw them up on twitter / adn / diaspora* / flickr / ello / imzy /whatever, with a bigger audience, and more interaction.
I was also feeling a bit self-conscious about standing up in public. After leaving last.fm (fairly amicably, as these things go, fwiw, albeit with a slightly battered heart), which felt like a fairly visible shift sideways, I was quite deliberately courting more obscure, maybe more unexpected job roles, and I remember feeling like I really didn't want to bare my thoughts to the internet judgement machine whilst I wasn't even entirely sure what I was doing myself a good deal of the time. Also busy! Young family plus startups really left little time for anything much else.
I also was really feeling the pain of Wordpress . I never quite managed to find an authoring approach to use with it that didn't make writing anything seem like far harder work than it ought to be, also because I always insist on self-hosting, the sheer weight of it for maintainence and security updates, and backups, and DBA -ing, and having to write PHP or perhaps even plugins to do the inevitable customisations someone like myself inevitably finds themselves suckered into doing. So Wordpress was a drag, which was feeding my reluctance to contribute much of substance. So I decided to pause on updating whilst, in true wannabe-hacker style, I whipped together some kind of alternative content publishing system.
I'll just take a paragraph out to stress that I actually admire WordPress a great deal. It's a very sophisticated and flexible web platform, and a great choice for site management, in either managed or self-hosted configuration. It kept this site ticking along for years. It just isn't a particularly good fit for my requirements, which are extremely simple
I thought about using another off-the-shelf blogging system, which would have been the sensible route, but I figured that would just lead to a similar frustrated stalemate. So I started to sketch out an application that would allow me to quickly fling out tagged and dated content without much overhead of hosting or writing. And I carried on intermittantly piecing this app together, often on trains, for a couple of years. As an exercise in procrastination, it worked out better than I expected, and I carried on posting short content to twitter and others, reasonably happy to continue to defer the responsibility.
But then the site went dark. I was hosting it all on a linode instance. I've been a very enthusiastic linode user for perhaps ten or more years, I think they have an excellent product, offering well-provisioned VPS instances , inexpensively, with an easy to use management site. Generally I've been very happy with them to date.
This changed somewhat last year, and my confidence deflated a little. There was an extended outage of service across linode in December 2015 , apparently as a result of a targetted DDOS . This lasted for many days, and the communications about it from linode were muted and suspiciously vague. This isn't really what I expect from a first-tier ISP. I came away with the impressions that there were some significant architectural problems with their infrastructure, probably from acrued technical debt , and potentially some exploitable vulnerabilities in their public facing application software . I decided it was time for a change.
I did some reasearch and rented a couple of new hosts. This time I've gone for low end, physical servers. This represented another procrastination opportunity, because when I originally set up the beatworm.co.uk linodes, almost ten years ago, I just hand configured everything by remote shell. Now I like to use the ansible configuration management system to set up hosts, and I took this opportunity to port my public infrastructure across to use repeatable playbooks. This turned into another major yak-shave , because there was slightly more to it than just a WordPress deployment, I was hosting mail, calendars, media streaming, IM, DNS, the works. After getting lost in this tarpit for a couple of months, I decided to move the application tier over to use the playbooks from the sovereign project , which covers much of the same ground, but is already written, and uses more modern components. Of course it wasn't entirely straightforward to integrate these plays over my existing base provisioning, and I ran into a couple of glitches and gotchas with some of the choices they'd made for configuration, but it only took a couple of weekends worth of fiddling to get it all running in a fairly acceptable shape. I moved the DNS across, at which point the wordpress site was left behind, and everything went dark.
I was surprised at how much this bothered me.
I like an outlet for sharing things. I enjoy the idea of having a stable internet identity . I don't like the way the modern web has folded these ideas into a handful of consumer products run by just a couple of corporate gatekeepers. That's not the web I grew up with, and it's not the web I want to see either. A very loosely federated ecosystem of ad-hoc resources, all mixed together as hypermedia, aggregated and accessed via an assorted bag of user-agents. That's how it works best . I like to write, because I like the practice and discipline of working toward articulating my thoughts for a general reader.
I like being able to curate an archive, and keep control over how that information persists and is presented. This is hard enough to do when you have primary jurisdiction over the medium and material (there is plenty of bitrot on view in my archive, particularly in the really old material, which has been migrated across multiple publishing platforms now), and basically impossible if you're relying on a third party service, which periodically re-invents itself to better serve it's own objectives, which are only ever to be tangentally aligned with your own, at best.
I don't like the sense of obligation I get from formal social media platforms. There's a subliminal sense of pressure to perform, to update, to observe the conventions, to consider and measure the implied audience. I'm not a joiner by nature. I just end up gently resenting the throng. I like to feel like I have a voice, but I don't want, or even expect to reach, an automatically provided audience.
So, I picked back up my now-neglected website platform experiment, and knocked it together enough to get an MVP out of the door. It serves HTML over HTTP. It has a relatively minimal set of style rules that should allow it to work gracefully across various screen dimensions. It has rudimentary support for RSS ( not that many people use newsreaders any more ). It's simple to run in a staging environment, and I can write posts in plain text in emacs , and edit and post them without much extra grief. It's only got about 22% of the functionality I had originally planned, but I feel the urge to ship it, use it, and hopefully I'll refine it in production.
There's a couple of interesting quirks to this new hosting setup. It's an ARM -based micro-blade, hosted on a scaleways C1 . The blogging software is semi-static , in as much as it serves generated content from the filesystem. It's written in common lisp , and deployed in a different lisp to the one it's developed on There's no frameworks (aside from using zurb foundation classes to base the CSS). There's no database. There's no comments, because I haven't yet decided on a productive way to support them.




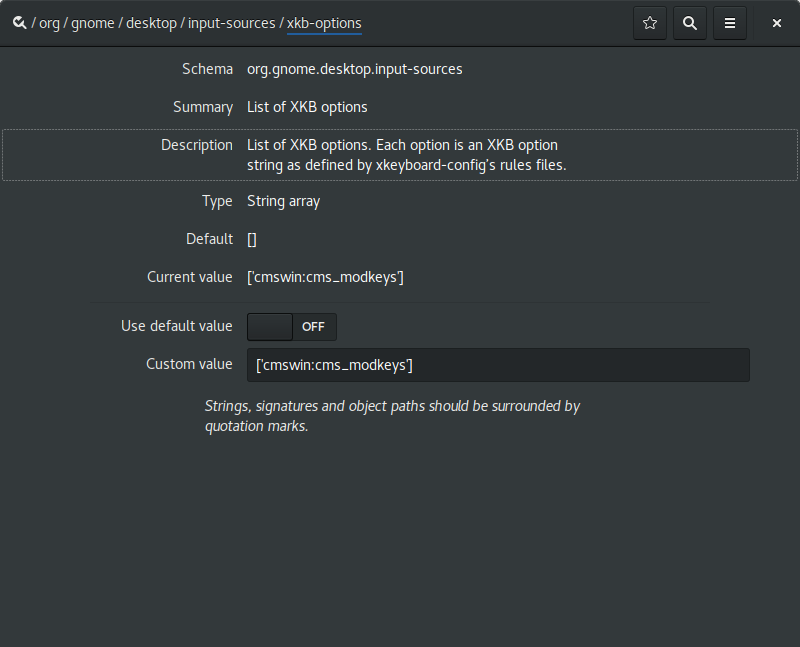

{kind=link}
{kind=link}